

Los investigadores de Redmond lanzaron un modelo de lenguaje pequeño entrenado con datos de calidad.
Microsoft anunció el lanzamiento de Phi-2, un modelo de lenguaje pequeño (SML, por sus siglas en inglés) capaz de superar a Llama 2 y otros competidores.
Desarrollado por Microsoft Research, el modelo demostró excelentes capacidades de razonamiento y comprensión de lenguaje.
Los investigadores realizaron múltiples pruebas y encontraron que se desempeña mejor que la inteligencia artificial de Meta y Google en algunas tareas.
Phi-2 forma parte de una familia de modelos basados en transformadores que tienen una cantidad menor de parámetros.
De acuerdo con Microsoft, la idea detrás de su desarrollo se basa en la premisa de que es posible lograr un rendimiento cercano a los modelos más extensos, como Llama o Mistral.
Para tener una idea de la escala, Phi-2 cuenta con 2.700 millones de parámetros, mientras que GPT-4 tendría unos 1.700 billones.
Pese a esta limitante, la inteligencia artificial de Microsoft iguala o supera a modelos hasta 25 veces más grandes.
En una serie de pruebas de matemáticas y programación, Phi-2 logró un mejor rendimiento que Llama 2, la IA de Meta.
Los desarrolladores fueron más lejos y lo pusieron frente a Gemini Nano 2, en donde consiguió resolver problemas de física de un modo parecido a la inteligencia artificial de Google.
“Con solo 2,7 mil millones de parámetros, Phi-2 supera el rendimiento de los modelos Mistral y Llama-2 en los parámetros 7B y 13B en varios puntos de referencia agregados”, mencionaron los desarrolladores.
“En particular, logra un mejor rendimiento en comparación con el modelo Llama-2-70B 25 veces más grande en tareas de razonamiento de varios pasos, es decir, codificación y matemáticas.”
¿Cómo fue posible conseguir estos resultados con menos parámetros?
El secreto está en el entrenamiento.
Phi-2 se entrenó con un conjunto que incluye textos sintéticos de PNL, subconjuntos de código obtenidos de Stack Overflow, competencias de programación y más.

Microsoft mencionó que la calidad de los datos de entrenamiento juega un papel fundamental en el rendimiento del modelo.
A diferencia de GPT-4, Microsoft realiza una curación de datos web que se filtran según su valor educativo.
El equipo de investigadores utilizó un conjunto “con calidad de libros de texto”, una estrategia que se aplica desde la primera versión de Phi.
“Nuestra combinación de datos de entrenamiento contiene conjuntos de datos sintéticos creados específicamente para enseñar al modelo razonamiento con sentido común y conocimientos generales, incluida la ciencia, las actividades diarias y la teoría de la mente, entre otros”.
El entrenamiento de Phi-2 tomó 14 días y se utilizaron 96 tarjetas gráficas A100 de NVIDIA.
Pese a que no se hizo un refinamiento adicional, el SML ofrece menos toxicidad y sesgo en sus respuestas, comparado con Llama 2.
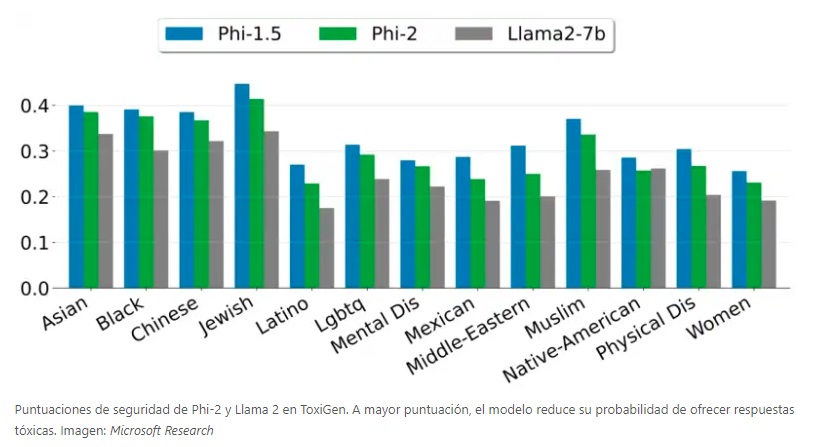
Microsoft Research comentó que efectuaron pruebas exhaustivas con benchmarks académicos, así como también herramientas internas.
Lamentablemente, Phi-2 solo estará disponible para proyectos de investigación.
El SML se ofrecerá como parte de Azure AI Studio para fomentar el desarrollo de modelos de lenguaje.
La licencia actual no permite utilizarlo en aplicaciones comerciales, como ChatGPT.
Fuente: Microsoft
Artículos relacionados:
 Microsoft presenta inteligencia artificial capaz de interpretar imágenes y resolver acertijos
Microsoft presenta inteligencia artificial capaz de interpretar imágenes y resolver acertijos  Meta anuncia LlaMA 2, su inteligencia artificial de código abierto
Meta anuncia LlaMA 2, su inteligencia artificial de código abierto  Microsoft crea inteligencia artificial capaz de imitar la voz de cualquier persona en tres segundos
Microsoft crea inteligencia artificial capaz de imitar la voz de cualquier persona en tres segundos  Google Gemini, el modelo de inteligencia artificial más avanzado a la fecha
Google Gemini, el modelo de inteligencia artificial más avanzado a la fecha  Desarrollan una inteligencia artificial para detectar cáncer “capaz de superar a los expertos humanos”
Desarrollan una inteligencia artificial para detectar cáncer “capaz de superar a los expertos humanos”  Microsoft presenta su aplicación de noticias con inteligencia artificial para web, Windows 10, Android, iOS
Microsoft presenta su aplicación de noticias con inteligencia artificial para web, Windows 10, Android, iOS