
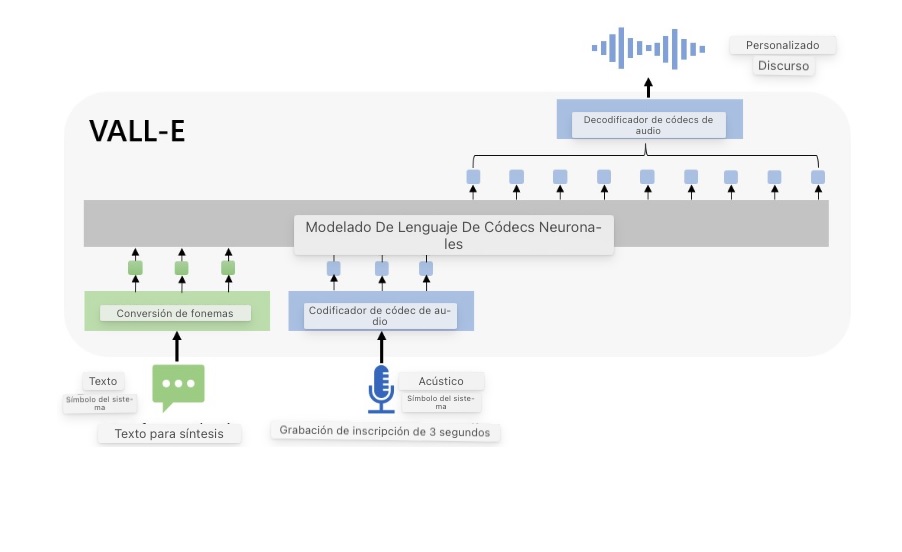
El nuevo modelo de lenguaje para la síntesis de texto a voz es capaz de replicar la voz de cualquier hablante con tan solo escuchar 3 segundos de audio.
Microsoft está apostando fuerte por GPT-3, la inteligencia artificial diseñada por OpenAI, para varias de sus aplicaciones y servicios, como Bing o Word.
La compañía dirigida por Satya Nadella, sin embargo, también se encuentra desarrollando modelos propios.
Prueba de ello es VALL-E, una IA capaz de imitar la voz de cualquier persona con tan solo escuchar tres segundos de audio.
VALL-E, en concreto, es un modelo de lenguaje para la síntesis de texto a voz (TTS) basado en EnCodec, el códec de audio de Meta, y es muy similar a otras IA que permiten generar audios a través de una breve descripción de texto.
La propia Microsoft, de hecho, cuenta con un servicio similar: Text to Speech, que permite convertir texto en voz sintetizada.
La diferencia, sin embargo, es que VALL-E es capaz de analizar la voz de una persona, para posteriormente interpretar cómo sonaría esa voz con diferentes frases.
Todo ello, además, preservando la entonación y la emoción del hablante, afirma la compañía.
Y puede lograr grandes resultados con solo tres segundos de voz.
“Específicamente, entrenamos un modelo de lenguaje de códec neuronal (llamado VALL-E) utilizando códigos discretos derivados de un modelo de códec de audio neuronal estándar, y consideramos TTS como una tarea de modelado de lenguaje condicional en lugar de una regresión continua de señal como en trabajos anteriores.”
La nueva IA de Microsoft capaz de replicar la voz de cualquier persona, además, puede usarse con otros modelos de IA generativa.
Entre ellos, GPT-3.
De este modo, los usuarios, por ejemplo, podrían pedirle a ChatGPT que imite la voz de un individuo específico.
El objetivo, por tanto, es poder crear discursos de voz a través de una introducción de texto.
Esto, sin embargo, trae consigo un inconveniente importante.
Si finalmente VALL-E está disponible para el público, muchos podrían utilizarla para suplantar la identidad de las personas.
Microsoft, en este caso, detalla que “es posible construir un modelo de detección para discriminar si un clip de audio ha sido sintetizado por VALL-E”.
Fuente: VALL-E
Artículos relacionados:
 Inteligencia artificial capaz de predecir el rostro de una persona con solo escuchar su voz
Inteligencia artificial capaz de predecir el rostro de una persona con solo escuchar su voz  Generador de voz artificialmente inteligente puede imitar cualquier voz
Generador de voz artificialmente inteligente puede imitar cualquier voz  Inteligencia artificial capaz de hacer discursos con su voz
Inteligencia artificial capaz de hacer discursos con su voz  Inteligencia artificial capaz de mezclar la cara de una persona con la de cualquier animal
Inteligencia artificial capaz de mezclar la cara de una persona con la de cualquier animal  IBM crea lengua electrónica con inteligencia artificial capaz de identificar la composición química de cualquier líquido
IBM crea lengua electrónica con inteligencia artificial capaz de identificar la composición química de cualquier líquido  Inteligencia artificial crea audio a partir de texto
Inteligencia artificial crea audio a partir de texto