

Investigadores crearon y utilizaron redes neuronales complejas para recrear el habla a partir de grabaciones cerebrales y luego utilizaron esa recreación para analizar los procesos que impulsan el habla humana.
La producción del habla es un fenómeno neuronal complejo que ha dejado a los investigadores sin palabras para explicarlo.
Separar la compleja red de regiones neuronales que controlan el movimiento muscular preciso en la boca, la mandíbula y la lengua de las regiones que procesan la retroalimentación auditiva de escuchar su propia voz es un problema complejo que debe superarse para la próxima generación de prótesis que produzcan habla.
Ahora, un equipo de investigadores de la Universidad de Nueva York ha realizado descubrimientos clave que ayudan a desenredar esa red y la están utilizando para crear una tecnología de reconstrucción vocal que recrea las voces de pacientes que han perdido la capacidad de hablar.
El equipo, codirigido por Adeen Flinker, profesor asociado de Ingeniería Biomédica en NYU Tandon y Neurología en la Facultad de Medicina Grossman de NYU, y Yao Wang, profesor de Ingeniería Biomédica e Ingeniería Eléctrica e Informática en NYU Tandon, así como miembro de NYU WIRELESS: creó y utilizó redes neuronales complejas para recrear el habla a partir de grabaciones cerebrales, y luego utilizó esa recreación para analizar los procesos que impulsan el habla humana.
La producción del habla humana es un comportamiento complejo que implica el control anticipado de las órdenes motoras, así como el procesamiento de retroalimentación del habla autoproducida.
Estos procesos requieren la participación de múltiples redes cerebrales en conjunto.
Sin embargo, ha sido difícil disociar el grado y el momento del reclutamiento cortical para el control motor versus el procesamiento sensorial generado por la producción del habla.
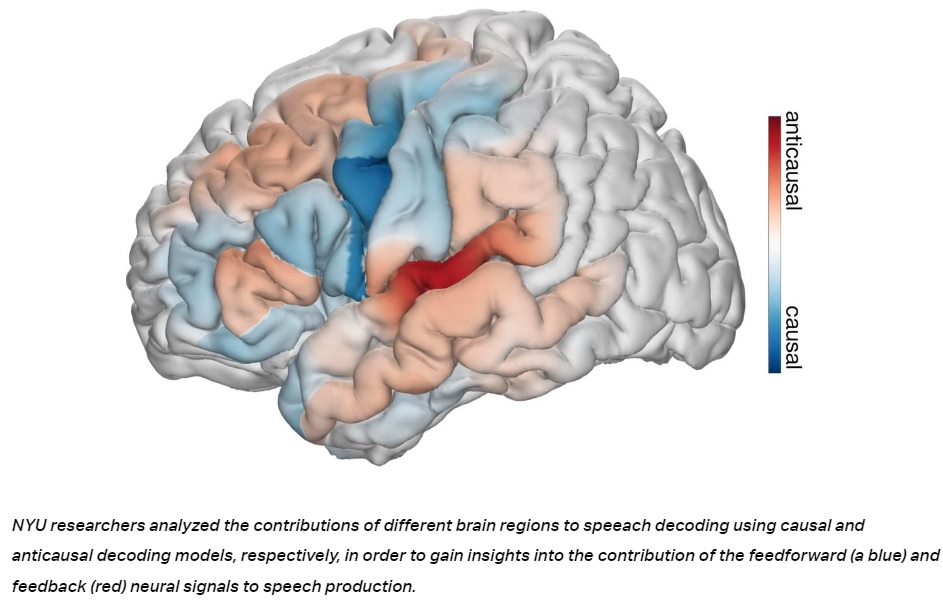
Los investigadores han desentrañado con éxito los intrincados procesos de retroalimentación y avance durante la producción del habla.
Utilizando una innovadora arquitectura de aprendizaje profundo en grabaciones neuroquirúrgicas humanas, el equipo empleó un sintetizador de voz diferenciable basado en reglas para decodificar parámetros del habla a partir de señales corticales.
Al implementar arquitecturas de redes neuronales que distinguen entre convoluciones temporales causales (usando señales neuronales actuales y pasadas para decodificar el habla actual), anticausales (usando señales neuronales actuales y futuras) o una combinación de ambas (no causales), los investigadores pudieron analizar meticulosamente las contribuciones del feedforward y la retroalimentación en la producción del habla.
“Este enfoque nos permitió desenredar el procesamiento de señales neuronales de retroalimentación y retroalimentación que ocurren simultáneamente mientras producimos el habla y sentimos la retroalimentación de nuestra propia voz“, dice Flinker.
Este enfoque de vanguardia no solo decodificó parámetros interpretables del habla, sino que también proporcionó información sobre los campos receptivos temporales de las regiones corticales reclutadas.
Sorprendentemente, los hallazgos desafían las nociones predominantes que segregan la retroalimentación y las redes corticales de retroalimentación.
Los análisis revelaron una arquitectura matizada de retroalimentación mixta y procesamiento anticipado, que abarca las cortezas frontal y temporal.
Esta novedosa perspectiva, combinada con un rendimiento excepcional de decodificación del habla, marca un importante avance en nuestra comprensión de los intrincados mecanismos neuronales que subyacen a la producción del habla.
Los investigadores han utilizado esta nueva perspectiva para informar su propio desarrollo de prótesis que pueden leer la actividad cerebral y decodificarla directamente en el habla.
Si bien muchos investigadores están trabajando en el desarrollo de tales dispositivos, el prototipo de la Universidad de Nueva York tiene una diferencia clave: es capaz de recrear la voz del paciente, utilizando sólo un pequeño conjunto de grabaciones, en un grado notable.
El resultado puede ser que los pacientes recuperen la voz después de perderla.
Esto es gracias a una red neuronal profunda que tiene en cuenta un espacio auditivo latente y puede entrenarse con solo unas pocas muestras de una voz individual, como un video de YouTube o una grabación de Zoom.
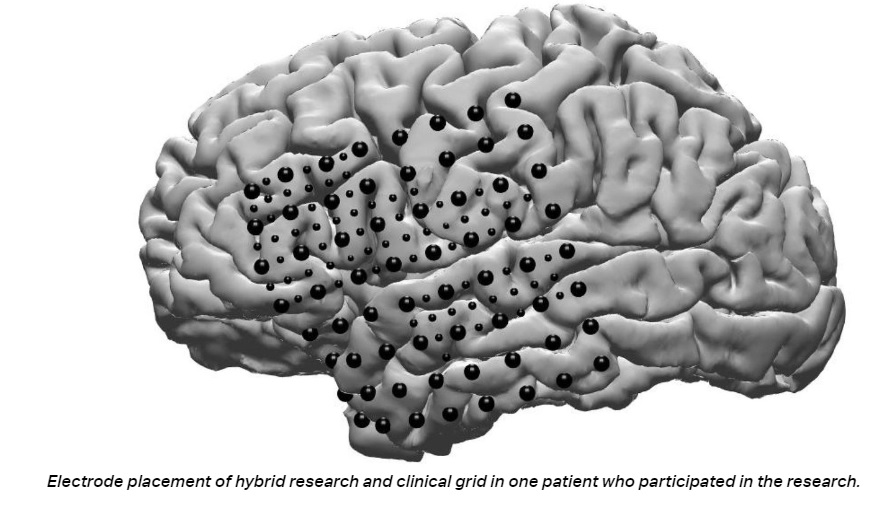
Para recopilar los datos, los investigadores recurrieron a un grupo de pacientes que padecen epilepsia refractaria, actualmente intratable con medicamentos.
A estos pacientes se les implanta una rejilla de electrodos subdurales de EEG en sus cerebros durante un período de una semana para monitorear sus condiciones, y aceptaron 64 electrodos más pequeños adicionales intercalados entre los electrodos clínicos regulares.
Proporcionaron a los investigadores información clave sobre la actividad cerebral durante el acto de producción del habla.
Fuente: PNAS
Artículos relacionados:
 Inteligencia artificial convierte actividad cerebral en habla
Inteligencia artificial convierte actividad cerebral en habla  Reconstruyen imágenes en 3D a partir de reflejos oculares
Reconstruyen imágenes en 3D a partir de reflejos oculares  Desarrollan un método revolucionario para lograr animación del habla en tiempo real
Desarrollan un método revolucionario para lograr animación del habla en tiempo real  Científicos registran la actividad cerebral de una persona mientras moría, resultados asombrosos
Científicos registran la actividad cerebral de una persona mientras moría, resultados asombrosos  Logran registrar la actividad cerebral de forma inalámbrica a lo largo del día
Logran registrar la actividad cerebral de forma inalámbrica a lo largo del día  Un implante de grafeno detecta actividad cerebral a frecuencias extremadamente bajas
Un implante de grafeno detecta actividad cerebral a frecuencias extremadamente bajas